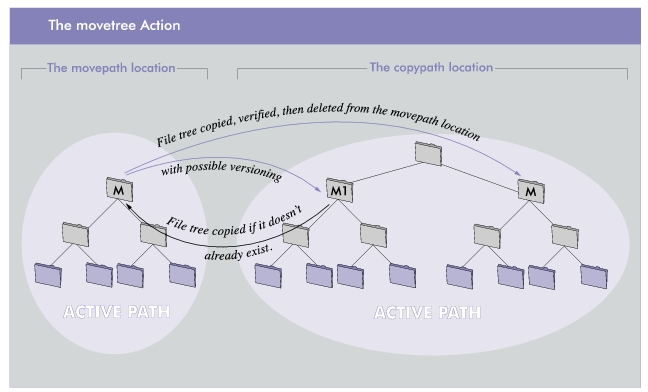
This movetree Action shuttles files and directories between one path in the file system and another, maintaining any underlying directory structure throughout operations. This is useful for archive-to-disk implementations where you want to move a set of data from a live production area to an “archive” area, then sometime later, copy it back.
The movetree Action requires two arguments: namely, the two paths between which you want to move a tree of directories and subdirectories. The following figure shows how you specify the paths:
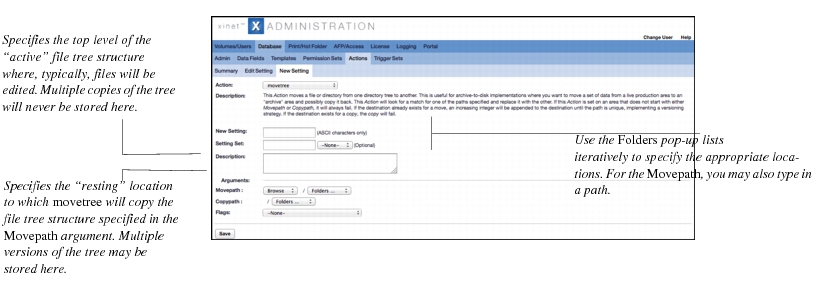
Incidentally, you may also use custom keyword values in the Movepath Argument. To do so, choose
Path from the
Movepath pop-up list rather than
Browse, so you can enter the path. Then enter the correct path in the field, appending
$KEYWORD###_VALUE at the end of the path, where
XXX is the
Data Field’s keyword value. If you do not know the value, the easiest way to look it up is to check the
Database, Data Fields, Summary page. The
ID column displays the number for each
Data Field.
After successfully copying all the files, the
Action removes the original files from the
Movepath, leaving that location empty for the time being. (Copying first, then verifying success before removing the files, rather than simply moving them, ensures that no data will be lost should something go wrong during the transfer.)
This will allow personnel with appropriate User Permissions. An
Image Info window displays, allowing archiving to disk and restoration. Once you’ve finished setting up the
Trigger and
Action, changing this piece of metadata allows them to move file trees between the archive and live path and vice versa.
[optional] If you wish, you could set up a second
Data Field and
movetree Action that would move files from the archive location to a different path than the one where it originally resided. Continuing the example above—where we’ve just set changes to the
archive_restore Data Field to move files between
/space/movetree_live and
/space/movetree_archived—we could create a second
Data Field for the
Image Info dialog, called
archive_alt_restore, which could be set to move files between
/space/movetree_archive and
/space/movetree_alt_restore, in effect implementing a restore-to-alternative-path archive-to-disk. strategy that once again would maintain a version system within the
/space/movetree_archive path.
One option is to keep all work that might be reused in place in the production area. This means all the data on a fast RAID system and leaving it in place where it was created as long as it might be reused, either with one Xinet volume or several, depending on access and organization needs. This scenario is appropriate for customers that have data that is accessed often, but has a limited longevity. This system also assumes a skilled and disciplined production crew that can be relied on to manage the production files in a consistent and regimented manner.
The scenario that most mimics traditional archive-to-tape is a setup, where the fast production area is “live” and the other disk is essentially a read only, retrieve-on-demand storage area. This is quite easy to implement with Xinet using Triggers and
Actions. A
Trigger to move to the archive area can be set up (and usually applied to a button with a Xinet Portal tag). It is trivial to restrict who can archive, and if you wish you can easily implement an approval process here. For example, most users’ requests to archive could simply execute a
Trigger to send e-mail with a hot-link to a manager. The manager can choose to archive (which actually does the
move) or not. The other volume has no access privileges (but is searchable and all previews,
mviews, metadata, etc. are available). A button that triggers a copy back to the production volume (either to its original location or with a path mapping, via a custom
Action) allows users to begin reusing the job immediately.
Trigger Set Configuration and
More Details about Triggers and Actions provide more information about Xinet
Triggers and
Actions.
Another option is to use the Xinet Portal Asset Fulfillment Request plug-in, which requires administrative approval for restoration requests before the files are placed in a retrieval area. More complex systems (for example, file versions that are archived again after being used again) are also possible to implement using
Triggers and
Actions if desired.
An example of a shop that would use this is one with a large, floating production staff. Only the person in charge of the job would be able to sign it off for archive (generally when it is approved) and a complete record of all produced jobs is maintained. Note that it is not difficult to implement Option 2 and 3 at the same time, with some users given large amounts of control and other users very little by using Xinet permissions and Permission Sets. You can also choose to make the migration to archive more programmatic (by date, access, etc.) rather than by human control if you wish. Retrieval from archive can also be controlled. For example, you might want to pass all non in-house images that are more than a year old by Legal to ensure that rights have been checked. The flexibility of metadata-driven
Triggers and
Actions allow you to make this as controlled as you wish.